The good 'ol argument about HTML vs. XHTML seems to have resurfaced on the Internets. I have been firmly in the XHTML camp at one time, but I had made a mention in a previous post about why I think that there was no point in fighting this battle anymore. There is a clear winner - HTML.
Of the lot of recent posts out there about which is better than the other, this little thought experiment echoes my sentiments about XHTML vs. HTML.
You pore through the raw source code of the page and find what you think is the problem, but it’s not in your content. In fact, it’s in an auto-generated part of the page that you have no control over. What happened was, someone linked to you, and when they linked to you they sent a trackback with some illegal characters (illegal for you, not for them, since they declare a different character set than you do). But your publishing tool had a bug, and it automatically inserted their illegal characters into your carefully and validly authored page, and now all hell has broken loose.
The emails are really pouring in now. You desperately jump to your administration page to delete the offending trackback, but oh no! The administration page itself tries to display the trackbacks you’ve received, and you get an XML processing error. The same bug that was preventing your readers from reading your published page is now preventing you from fixing it!
The fact is today's web is one where content might pour in from various locations, many of which you might not have control over. It is important to inter-operate with these kinds of content sources. Expecting strictness from an external source is not only overkill, it's folly to do so.
I had faced this problem when I had worked on the Sacramento Kings website. The content was coming from various sources, some even as trustworthy (for them at least) as the NBA. However, content encoding and ill formed markup issues were huge enough to get the JavaScript all crazy. I can't even imagine the amount of problems I'd have faced if we'd have decided to use a XHTML strict, or even transitional, doctype for this job. How can we force a content author to ensure that his content validates, and that the reference validation for your site and the reference validation for the content author is the same?
Simply use HTML. Let the onus of making sense of the content lie with the browser. It's not a human's job to make content appealing to a computer. If a computer cannot understand it, it should work hard. Not the human.
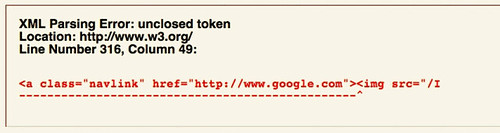
Just for the humor, check out this page that a friend happened to hit when pulling up W3.org the other day. I know I'm being harsh when I say this, but the guys who made the standard can't seem to respect it.

1 comment:
Awesome content. Keep up the good work! water heater repair in denver
Post a Comment